In the previous post we talked about the reasons for rewrite, design and implementation issues, and basic ideas. Now it's time to get to details. Today we'll mostly talk about command definitions, or rather interface definitions, since set commands is just one way to access the configuration interface.
Let's review the VyConf architecture (I included a few things in the diagram that we haven't discussed yet, ignore them for now):
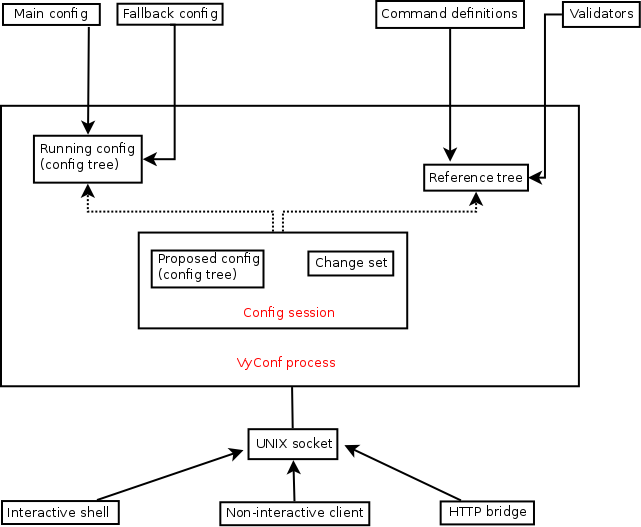
At startup, VyConf will load the main config (or the fallback config, if that fails). But to know whether the config is valid, and to know what programs to call to actually configure the target applications, it needs additional data. We'll call that data "interface definitions" since it defines the configuration interface. Specifically, it defines:
- What config nodes (paths) are allowed (e.g. "interfaces ethernet", or "protocols ospf")
- What values are valid for that nodes (e.g. any IPv4 or IPv6 address for "system name-server")
- What script/program should be called when this or that part of the config is changed
The old way
This is a typical template file:
vyos@vyos# cat /opt/vyatta/share/vyatta-cfg/templates/interfaces/ethernet/node.tag/speed/node.def
type: txt
help: Link speed
default: "auto"
syntax:expression: $VAR(@) in "auto", "10", "100", "1000", "2500", "10000"; "Speed must be auto, 10, 100, 1000, 2500, or 10000"
allowed: echo auto 10 100 1000 2500 10000commit:expression: exec "\
/opt/vyatta/sbin/vyatta-interfaces.pl --dev=$VAR(../@) \
--check-speed $VAR(@) $VAR(../duplex/@)"update: if [ ! -f /tmp/speed-duplex.$VAR(../@) ]; then
/opt/vyatta/sbin/vyatta-interfaces.pl --dev=$VAR(../@) \
--speed-duplex $VAR(@) $VAR(../duplex/@)
touch /tmp/speed-duplex.$VAR(../@)
fival_help: auto; Auto negotiation (default)
val_help: 10; 10 Mbit/sec
val_help: 100; 100 Mbit/sec
val_help: 1000; 1 Gbit/sec
val_help: 2500; 2.5 Gbit/sec
val_help: 10000; 10 Gbit/sec
We can spot a few issues with it already. First, the set of definitions is a huge directory tree where each directory represents a config node, e.g. "interfaces ethernet address" will be "interfaces/ethernet/node.tag/address/node.def". This makes them hard to navigate, you need to read a lot of small files to get the whole picture, and you need to do a lot of file/directory hopping to edit them. Now, try mass editing, or checking for mistakes before release...
Next, they use a custom syntax, which needs custom lexer and parser, and custom documentation (in practice, the source is your best bet, though I did write something of a syntax reference). No effortless parsing, no effortless analysis or transformation either.
Next, the value checking has its peculiarities. There is concept of type (it can be txt, u32, ipv4, ipv4net, ipv6, ipv6net, and macaddr), and there is "syntax:expression:" thing which partially duplicate each other. The types are hardcoded in the config backend and cannot be added without modifying it, even though they only define validation procedure and are not used in any other way. The "syntax:expression:" can be either "foo in bar baz quux", or "pattern $regex", or "exec $externalScript".
But, the "original sin" of those files is that they allow embedded shell scripts, as you can see. Mixing data with logic is rarely a good idea, and in this case it's especially annoying because a) you cannot test such code other than on a live system b) you have to read every single file in a package to get the complete picture, since any of them may have embedded shell.
Now to the new way.
The new way
Now when we discussed some issues with the old way, we are ready to state the requirements for the new way. It should:
- Be purely declarative
- Not be a custom format (easier to use and easier to learn for the contributors)
- Be easily observable
The format
My idea is to use XML for those. I expected that after my previous post, people will come and object to OCaml. Either I was so persuasive, or no one got to that part of the post. Well, I bet XML will get objections, and I'll respond to it in advance. The reason XML has so much of a bad reputation is that it's often used in wrong places, or used improperly. The great thing about XML that justifies its bulkiness is that it enables the rest of the technology stack to work, namely XML Schema/RelaxNG, XSLT, XQuery, XPath... Unlike any other format, it has ready to use tools for formal description and verification, transformation, and querying.
XML Schema (in generic sense, either XSD or RelaxNG) allows me to formally define the valid grammar and share it with everyone so people don't need to guess or read the source to find out what exactly the grammar is. Examples are good but they invariably leave at leat some cases to guessing, and aren't machine verifiable. Schemas are, we can easily add schema check as a build step. I do something like:
$ rnv -q ./data/schemata/interface_definition.rnc data/examples/interface_definition_sample.xml && echo valid
valid
And I know that my file conforms to the schema. With XSLT, we can produce command reference right from those definitions without writing additional code, too. Ok, writing XSLT transforms can be tricky, but the rewards are great. There is no such tools for JSON or YAML, JSON Schema RFC draft never came to frutition. Just to make it clear, I don't suggest using XML for serialization format, though for the public API, XML RPC may be a good idea. Definitely not for internal communication though, no.
RelaxNG schema for the interface definitions was one of the first things I've made for the new backend, in its days as a prototype in Python, which I scraped for reasons already discussed in the previous post. I would feel bad for scraping it, but everything anyone else ever contributed to it was PEP8 fixes, so I don't feel bad for it really. We'll discuss what's in the schema now.
You can find the schema here: interface_definition.rnc
The taxonomy of config nodes
Well, before we get to describing the schema, we need to describe what the config is.
VyOS config, the multiway tree, consists of nodes with attached data. For the datastructure itself, there is no difference between nodes of course, but for the CLI and for scripts that handle the config, there is.
First, there are nodes that can have children (non-leaf nodes), and nodes that cannot (leaf nodes). For example, "protocols" node has children named "static", "bgp", "ospf" etc., which in terms has their own children. A typical leaf node is the "disable" node found in interfaces and many other places, it cannot have children.
Non-leaf nodes can have fixed or variable names. For example, the "protocols" node is always called "protocols". But we have nodes such as "interfaces ethernet" or "firewall name" that have children without predefined names, such as "interfaces ethernet eth0", or "firewall name Test". We call such nodes tag nodes. This is what they are called in current VyOS, I don't like this word much (what exactly is the tag here? "ethernet" or "eth0"?), but I don't see a better term. If you have any ideas, please share.
Leaf nodes are not all the same either. They differ in the number of values they can have. Node values (as in "system name-server 192.0.2.1") are not children, they are separate entities that are treated differently in value validation and config output and pretty much everywhere. We have valueless nodes that can't have any values at all, such as "disable", or "reboot-on-panic". We have nodes that can have only one value, such as "default-action" in firewall. We also have multivalue nodes, which we will call just multi nodes that can have many values, such as "address" under interfaces.
What do node types affect?
Tag nodes are rendered differently in the config output, "interfaces { ethernet eth0 { ..." rather than "interfaces {ethernet { eth0 { ...". While it's a trivial issue, I think it's easier to read and saves up some valuable vertical space.
Also, tag nodes, obviously, require child name validation (such as eth[0-9]+ for ethernet.
The number of allowed values in a leaf node affects the behaviour of the set operation. For normal nodes, set replaces the value, such as in "set system config-management commit-revisions 2000". For multi nodes, set appends a new value, as in "set system name-server 203.0.113.4".
New concept: order-preserving nodes
Things like firewall rulesets or route-maps are processed top down until the first match, and changing the order of rules can change the behaviour. This means there must be a way to preserve the order in the config output and in scripts.
Right now, the backend doesn't really care about the order, it's all in the output (which, due to bash limitations, sometimes sorts nodes in confusing order in completion), and in scripts. All nodes that must be ordered thus are forced to have numeric names to ensure unambiguous sorting.
There are a few annoying things about numbered rules. It's easy to configure yourself into a corner where you have to rename a lot of rules to insert a new one where it should be. If one used rules 1,2,3,4,5, they'll have to rename every single rule to create gaps. Myself, I normally leave gaps like 10,20,30, but even that runs out sometimes. Gaps like 100,200,300 would be future proof, but absurdly wide, combined with the current (completely arbitary!) limitation of 9999 rules in a single firewall. That limitation is not just in the validation code though, the assumption based on it is that the default action rule is internally numbered 10000, so changing it isn't exactly a one line fix.
JunOS doesn't use numbered rules, nodes such as firewall policies preserve child order, and there are commands to move nodes around. What I'm not very fond of though is that for a new node, you need to set it first, and then use "insert" command. I guess we could use a set option instead, e.g. a pseudo-pipe "set firewall name Foo rule block-ssh | before allow-all". Let's not focus on the command syntax yet, though.
What scripts to call when something changed: node owners
This one I have a mixed feeling about. While we already ruled out embedded logic in interface definitions, there's a question how granular node ownership can be.
Right now in the schema, any non-leaf nodes can have an "owner", a reference to separately defined "component" (such as "firewall", or "ospf"). I toyed with the idea to allow the owner attribute only for the top level node of each definition, but this may cause unnecessary fragmentation of definitions, e.g. inside "vpn", "vpn ipsec site-to-site" and "vpn ipsec profile" may legitimately have different owner, the site-to-site script and the DMVPN script respectively.
Components will be defined in separate XML files, see the schema. Component definition includes its name, scripts that must be run for checking if config is valid, generating application configs, and applying the changes to the system (I call them "verify", "update", and "apply" stages), and a list of dependencies.
The last part needs some elaboration. As you can easily see, there are things that must run in certain order, for example, IPv6 router advertisment should only be configured after the interfaces. Right now, VyOS uses hardcoded priorities for it, you can see them all by running "/opt/vyatta/sbin/priority.pl". They are taken from the priority: tag in templates.
There are two main issues with it. First, it's not very easy to track, you can only see them all on a live system, and it's not quite easy to see what really depends on what. Second, it absolutely rules out parallelized commits, even though most of components are independent and could easily be done in parallel.
The idea is to specify dependencies for each component instead, and use topological sort to determine the order at commit time, this way we can both easily see what the real dependencies are, and parallelize the commit.
Back in high school, we had a cool CS teacher. She was a part time teacher really, while her main job was image recognition research. She taught us a lot about algorithms and datastructures, and always emphasized the importance of learning the foundations of CS, rather than new hot things. I've had quite a geek crush on her. It's all irrelevant to the post of course, I'm just checking if you are still following. By the way, there's a a 15% discount to VyOS shirts.
Unsolved issue: pervasive components
By "pervasive" I mean things that exist in multiple places in the config. For example, we have "vrrp" subtree in ethernet, VLANs, bonding etc. We also have "ip ospf" subtree in literally every interface. And then, "firewall" is in every interface too. I still wonder how to handle this issue in the new backend.
Right now, we don't have real support for it. They are generated by scripts, such as this one. There are a few issues with this approach, first is that to add a new interface type, you need to modify a few unrelated packages, which makes life harder for contributors. The second issue is that it disperses the component logic over multiple places ("ip ospf bandwidth" under interfaces runs vtysh -c directly for instance), this is bad for system-wide consistency checks, and can make transactional rollback a lot harder to do.
I don't see an easy solution to this problem, however. If we use some kind of file inclusion, the primary scripts will not know where to look, since it may be hard to extract every such path, without knowing about every place that can include it (or we are back to making such scripts aware of every interface type etc.). A possible solution is to "notify" the right component when such a path changes, thus introducing a concept different from "ownership".
Lastly, the most radical solution that does have some appeal: not support it at all. It can as well be "protocols ospf interface eth0 bandwidth 10000", i.e. every subtree can be self-contained. It may also be easier to read. Though it's still radical, and I'm not sure if we have things that really would be harmed by this approach. Let me know what you think.
Value (and tag node name) validation
My idea is to abolish the concept of types, and instead use a single concept of a constraint instead. The only built-in constraint type I see useful is regex, due to its widespread use. The rest should be implemented with external validators. We can provide ready to use validation helpers for the common values, such as IPv4 and IPv6 hosts and networks, integer values etc.
The open question is if we should introduce "validator definition" files, or not. Right now my code assumes that they are loaded into a hashtable from somewhere, but I haven't implemented a loading mechanism yet.
Now I think that we should rather assume that validators are in say /usr/libexec/vyconf/validators and treat validator references as executable names. We cannot guarantee total absense of runtime errors anyway, if a validator is missing or crashes, we can simply assume the value is invalid to prevent invalid values from being entered (though for emergency cases when someone found a bug on a live system and can't commit, we should also introduce an option to ignore such errors, at user's own risk).
Conclusion
That's all for now. The open questions I want your feedback for:
- How to handle pervasive definitions ("ip ospf" or "firewall" under interfaces) in the new system
- How to load validators into the system, or if we should not introduce any indirection there and just use the names of helper executables and store them in a predefined location
In the next post we'll talk about the multiway tree and the implementation of set and delete commands, and open questions in that area.

Comments